Wait a minute, doesn't ML menu already tell you to do that?
- Welcome to Magic Lantern Forum.
News:
Etiquette, expectations, entitlement...
@autoexec_bin | #magiclantern | Discord | Reddit | Server issues
This section allows you to view all posts made by this member. Note that you can only see posts made in areas you currently have access to.
#8476
Raw Video / Re: intervallometer over 30 seconds does not work..stops after first picture alone!
June 21, 2013, 01:22:51 PM #8477
Raw Video / Re: New writing strategy - variable buffering
June 21, 2013, 01:15:47 PM
Just added a small startup optimization (speculative start): https://bitbucket.org/hudson/magic-lantern/commits/50209fff8bbb
Before, it was writing to the card as soon as there was one captured frame in the buffer. Even if this meant it was writing a little slower.
Now, it starts writing as soon as there is one frame captured, but the write command is issued in advance, for the entire contiguous memory area. Of course, subsequent frames will be captured while writing. As long as the file writing task is slower than frame capturing task, this trick will work.
(Don't confuse this with pre-buffering.)
Obviously, this technique is inherently unsafe. If, for some reason, the card controller starts writing 120% faster than we have measured, the risk is that we may save a frame that does not contain complete image data.
In theory, I can detect this situation, and I've added quite a few consistency checks. I did not encounter any lost frames yet.
Don't expect miracles from it. On my cards, I did not get any noticeable improvement, other than prettier buffer graphs (with large steps from the very beginning) and the mathematical proof that both startup and cruise "segments" are saved at the maximum speed possible with standard file I/O.
I expect it to work a little better on Ted's card, where yesterday's method didn't work very well.
And of course, since the optimization is a little unsafe, it's turned off by default.
Binary (same link): raw_rec.mo
Before, it was writing to the card as soon as there was one captured frame in the buffer. Even if this meant it was writing a little slower.
Now, it starts writing as soon as there is one frame captured, but the write command is issued in advance, for the entire contiguous memory area. Of course, subsequent frames will be captured while writing. As long as the file writing task is slower than frame capturing task, this trick will work.
(Don't confuse this with pre-buffering.)
Obviously, this technique is inherently unsafe. If, for some reason, the card controller starts writing 120% faster than we have measured, the risk is that we may save a frame that does not contain complete image data.
In theory, I can detect this situation, and I've added quite a few consistency checks. I did not encounter any lost frames yet.
Don't expect miracles from it. On my cards, I did not get any noticeable improvement, other than prettier buffer graphs (with large steps from the very beginning) and the mathematical proof that both startup and cruise "segments" are saved at the maximum speed possible with standard file I/O.
I expect it to work a little better on Ted's card, where yesterday's method didn't work very well.
And of course, since the optimization is a little unsafe, it's turned off by default.
Binary (same link): raw_rec.mo
#8478
Raw Video / Re: New writing strategy - variable buffering
June 21, 2013, 08:43:08 AM
Well... hacked preview has little or no effect on 5D2 afaik. I'd say try normal settings, global draw off, and compare with what you already have. Just make sure you have the same FPS and resolution for both.
#8479
Raw Video / Re: New writing strategy - variable buffering
June 21, 2013, 08:09:11 AM
@ted: the builds from a.d. contain a number of extra changes, e.g. allows non-mod16 resolutions (which I prefer to stay away from, for DMA alignment reasons), or auto-disabling global draw (I think this should be up to the user, not automatic).
This one is vanilla, there are no changes that I didn't review.
This one is vanilla, there are no changes that I didn't review.
#8480
Tragic Lantern / Re: Raw video on 50d and 40d
June 21, 2013, 07:44:26 AMQuote from: Andy600 on June 21, 2013, 01:30:06 AM
http://we.tl/ua04qhB1wp 12bit CDNG & Post frame grab Jpegs
I knew it... black level is wrong on all of them...
Can you take some silent pics in the same video mode, and send me the dng?
#8481
Tragic Lantern / Re: Raw video on 50d and 40d
June 21, 2013, 01:14:50 AM
Can you upload the DNGs for the sample frame grabs?
#8482
Feature Requests / Re: [DONE] RAW overexposure warning
June 20, 2013, 11:30:17 PM
If it's blinking, it's from Canon, turn it off...
#8483
Raw Video / Re: New writing strategy - variable buffering
June 20, 2013, 11:28:13 PM
And I've just got a proof that this strategy is far from optimal 
(read: some more improvements may be coming soon)
(read: some more improvements may be coming soon)
#8484
Feature Requests / Re: [DONE] RAW overexposure warning
June 20, 2013, 10:37:19 PM
I don't see any overexposure warnings in your screenshot.
#8485
Raw Video / Re: New writing strategy - variable buffering
June 20, 2013, 10:22:03 PM
Cool
The strategy is universal, it's trying to use the available resources in the best possible way. It measures the card speed on the fly.
You can use the module from my previous post on any camera (the code is portable). The autoexec and sym are only for 5D3.
The strategy is universal, it's trying to use the available resources in the best possible way. It measures the card speed on the fly.
You can use the module from my previous post on any camera (the code is portable). The autoexec and sym are only for 5D3.
#8486
Raw Video Postprocessing / Re: The CinemaDNG Discussion
June 20, 2013, 09:37:47 PM
Yes, 1024, 1500...
It's computed on the fly; I have no idea what the absolute range is.
FYI: http://lclevy.free.fr/cr2/#wb
It's computed on the fly; I have no idea what the absolute range is.
FYI: http://lclevy.free.fr/cr2/#wb
#8487
Raw Video / Re: New writing strategy - variable buffering
June 20, 2013, 07:46:17 PM
I didn't expect any improvement in continuous recording TBH.
But if you were getting around 1000 frames before, now you can expect to get around 10000 (which is almost continuous).
But if you were getting around 1000 frames before, now you can expect to get around 10000 (which is almost continuous).
#8488
Raw Video / Re: New writing strategy - variable buffering
June 20, 2013, 07:32:05 PM
So far, all the screenshots looked good, so we can disable the debug info and let it run at full speed.
#8489
Raw Video / Re: 550D raw video recording port official thread
June 20, 2013, 07:09:26 PM
You need to use a fisheye lens 
There is another way though. Find the menu item that says "raw video" and switch it to "off".
Or, even better, start the camera without Magic Lantern. It's not targeted at beginners.
There is another way though. Find the menu item that says "raw video" and switch it to "off".
Or, even better, start the camera without Magic Lantern. It's not targeted at beginners.
#8490
Feature Requests / Re: Focus peaking blobs or regions.
June 20, 2013, 07:05:55 PM
There are barely enough CPU resources to draw the dots...
#8491
Raw Video / Re: Idea for speed increase
June 20, 2013, 07:04:14 PM
Please see reply #1.
It's your job to do that.
It's your job to do that.
#8492
Raw Video / Re: New writing strategy - variable buffering
June 20, 2013, 06:51:56 PM
Straight from the card, not packaged:
raw_rec.mo - portable, should work on any camera
autoexec.bin and 5D3_113.sym - only for 5D3 1.1.3 (optional)
raw_rec.mo - portable, should work on any camera
autoexec.bin and 5D3_113.sym - only for 5D3 1.1.3 (optional)
#8493
Raw Video / Re: New writing strategy - variable buffering
June 20, 2013, 06:34:27 PM
@Rewind: did you find any screenshots on your card? can you upload them?
They are saved when recording stops (if the build was compiled with debug flags on, which is default right now).
They are saved when recording stops (if the build was compiled with debug flags on, which is default right now).
#8494
Raw Video / Re: interlaced video saving possible?
June 20, 2013, 06:18:45 PM
Duplicate, see http://www.magiclantern.fm/forum/index.php?topic=6654.0
#8495
Raw Video / Re: 60D RAW video - it's working !!!
June 20, 2013, 06:02:22 PM
Check memory usage. Define CONFIG_TCC_UNLOAD in modules.c (breaks ETTR), or make sure you don't load bolt_rec, or both.
#8496
Feature Requests / Re: PicoC or TCC Scripting (Module?)
June 20, 2013, 05:12:34 PM
Of course. One of the major advantages is that scripting module can be loaded only when needed.
e.g. picoc only when you want to interpret a script, tcc only when you want to compile one.
Scripting GUI will be always loaded, I think.
e.g. picoc only when you want to interpret a script, tcc only when you want to compile one.
Scripting GUI will be always loaded, I think.
#8497
Raw Video / New writing strategy - variable buffering
June 20, 2013, 05:08:30 PM
If you ever looked in the comments from raw_rec.c, you have noticed that I've stated a little goal: 1920x1080 on 1000x cards (of course, 5D3 at 24p). Goal achieved and exceeded - even got reports of 1920x1280 continuous.
During the last few days I took a closer look at the buffering strategy. While it was near-optimal for continuous recording (large contiguous chunks = faster write speed), there was (and still is) room for improvement for those cases when you want to push the recording past the sustained write speed, and squeeze as many frames as possible.
So, I've designed a new buffering strategy (I'll call it variable buffering), with the following ideas in mind:
* Write speed varies with buffer size, like this (thanks to testers who ran the benchmarks for hours on their cameras)
* Noticing the speed drop is small, it's almost always better to start writing as soon as we have one frame captured. Therefore, the new strategy aims for 100% duty cycle of the card writing task.
* Because large buffers are faster than small ones, these are preferred. If the card is fast enough, only the largest buffers will be touched, and therefore the method is still optimal for continuous recording. Even better - adding a bunch of small buffers will not slow it down at all.
* This algorithm will use every single memory buffer that can contain at least one frame (because small buffers are no longer slowing it down).
* Another cause of stopping: when the buffer is about to overflow, it's usually because the camera is trying to save a huge buffer (say a 32MB one), which will take a long time (say 1.5 seconds on slow SD cameras, 21MB/s). So, I've added a heuristic that limits buffer size - so, in this case, if we predict the buffer will overflow after only 1 second, we'll save only 20MB out of 32, which will finish at 0.95 seconds. At that moment, the capturing task will have a 20MB free chunk that can be used for capturing more frames.
* Buffering is now done at frame level, not at chunk level. This finer granularity allows me to split buffers on the fly, in whatever configuration I believe it's best for the situation.
* The algorithm is designed to adjust itself on the fly; for this, it does some predictions, such as when the buffer is likely to overflow. If it predicts well, it will squeeze a few more frames. If not... not
* More juicy details in the comments.
This is experimental. I've ran a few tests, played back a few videos on the camera, but that was all. I didn't even check whether the frames are saved in the correct order.
Build notes
- This breaks bolt_rec. Buffering is now done at frame level, not at chunk level, so bolt_rec has to be adjusted.
- The current source code has debug mode enabled - it prints funky graphs. You'll find them on the card.
- The debug code will slow down the write speed.
- I'd like you to run some test recordings and paste the graphs - this will allow me to check if there's any difference between theory and practice (you know, in theory there isn't any).
- I did not run any comparison with the older method on the camera (I did only in simulation). Would be very nice if you can do this.
- It may achieve lower write speeds. This is normal, because it also uses smaller buffers. If you also consider the idle time, it should be better overall.
- For normal usage, disable the debug code (look at the top of raw_rec.c).
History
[2013-05-17] Experiment about checking the optimal buffer sizes. People ran the benchmarks for hours on their cameras and posted a bunch of logs. They pretty much confirmed my previous theory, that any buffer size between 16MB and 32MB should result in highest speeds.
[2013-05-30] Noticed that file writes aligned at 512 bytes are a little faster (credits: CHDK). Rounded image size to multiples of 64x32 or 128x16 to ensure 512-byte rounding.
[2013-08-06] Figured out that I could just add some padding to each frame to ensure 512-byte rounding and keep the high write speeds without breaking the converters too hard. Also aligned everything at 4096 bytes, which solved some mysterious lockups from EDMAC and brought back the highest speed in benchmarks (over 700MB/s).
[2013-05-30] speedsim.py - First attempt to get a mathematical model of the recording process. Input: resolution, fps and available buffers. Output: how many frames you will get, with detailed graphs. Also in-camera estimation of how many frames you will get with current settings.
[2013-06-18] Took a closer look at these logs and fitted a mathematical model for the speed drop at small buffer sizes.
[2013-06-18] Does buffer ordering/splitting matter? 1% experimented with it before, but there was no clear conclusion.
* is it better to take the highest one first or the smallest one first? there's no clear answer, each one is best for some cases and suboptimal for others.
* since some cameras had very few memory chunks (e.g. 550D: 32+32+8 MB), what if each of the 32MB buffer is divided in 2x16 or 4x8 MB? This brought a significant improvement for resolutions just above the continuous recording threshold, but lowered performance for continuous recording.
* optimization: updated speedsim.py so it finds the best memory configuration for one particular situation. Xaint confirmed the optimization results on 550D.
* problem: there was no one-size-fits-all solution.
[2013-06-19] Simulation now matches perfectly the real-world results. So, the mathematical model is accurate!
[2013-06-19] Started to sketch the variable buffering algorithm and already got some simulation results. There was a clear improvement for borderline cases (settings that require just a little more write speed that your camera+card can deliver).
Example: 550D, 1280x426, 23.976fps, 21.16MB/s, simulation:
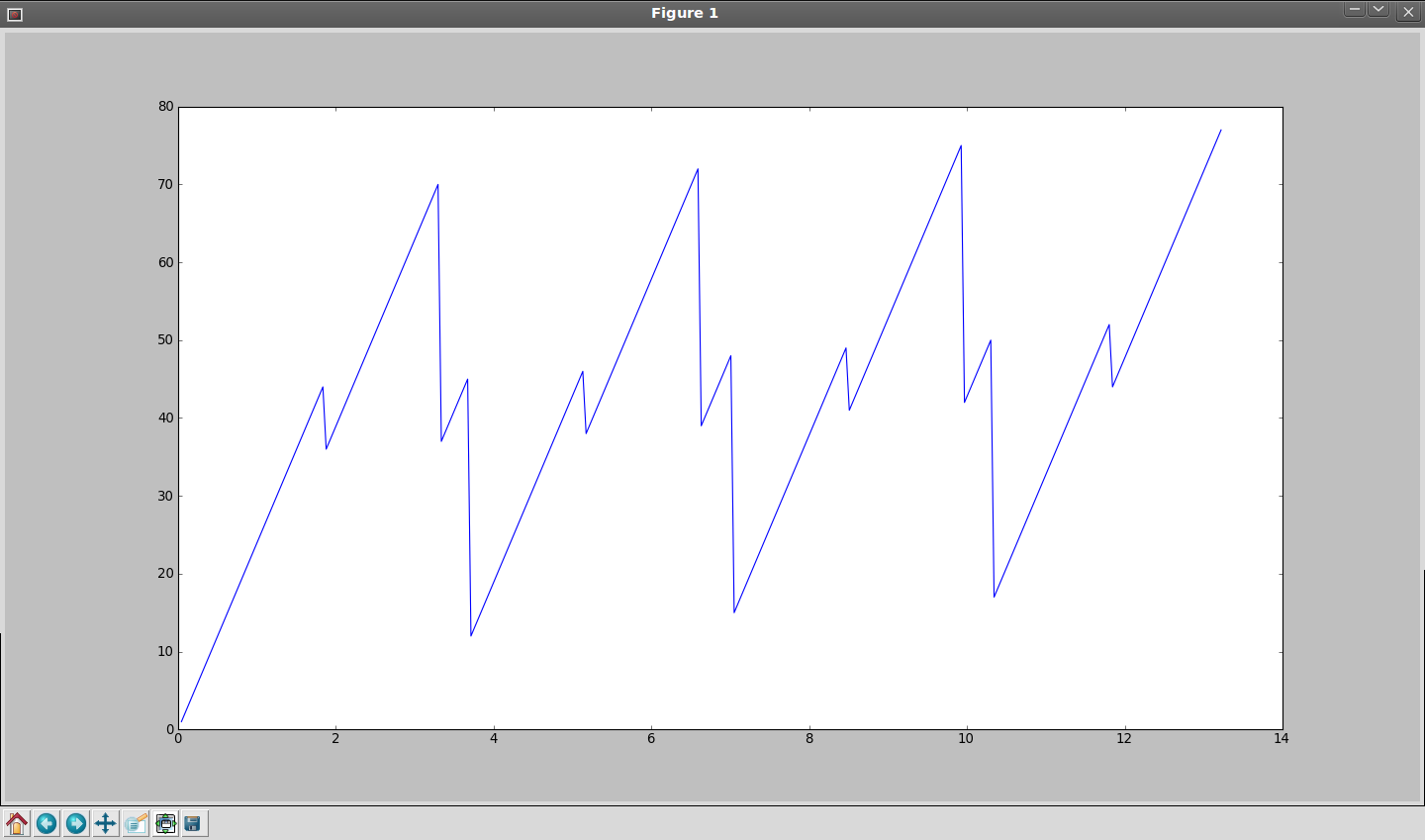
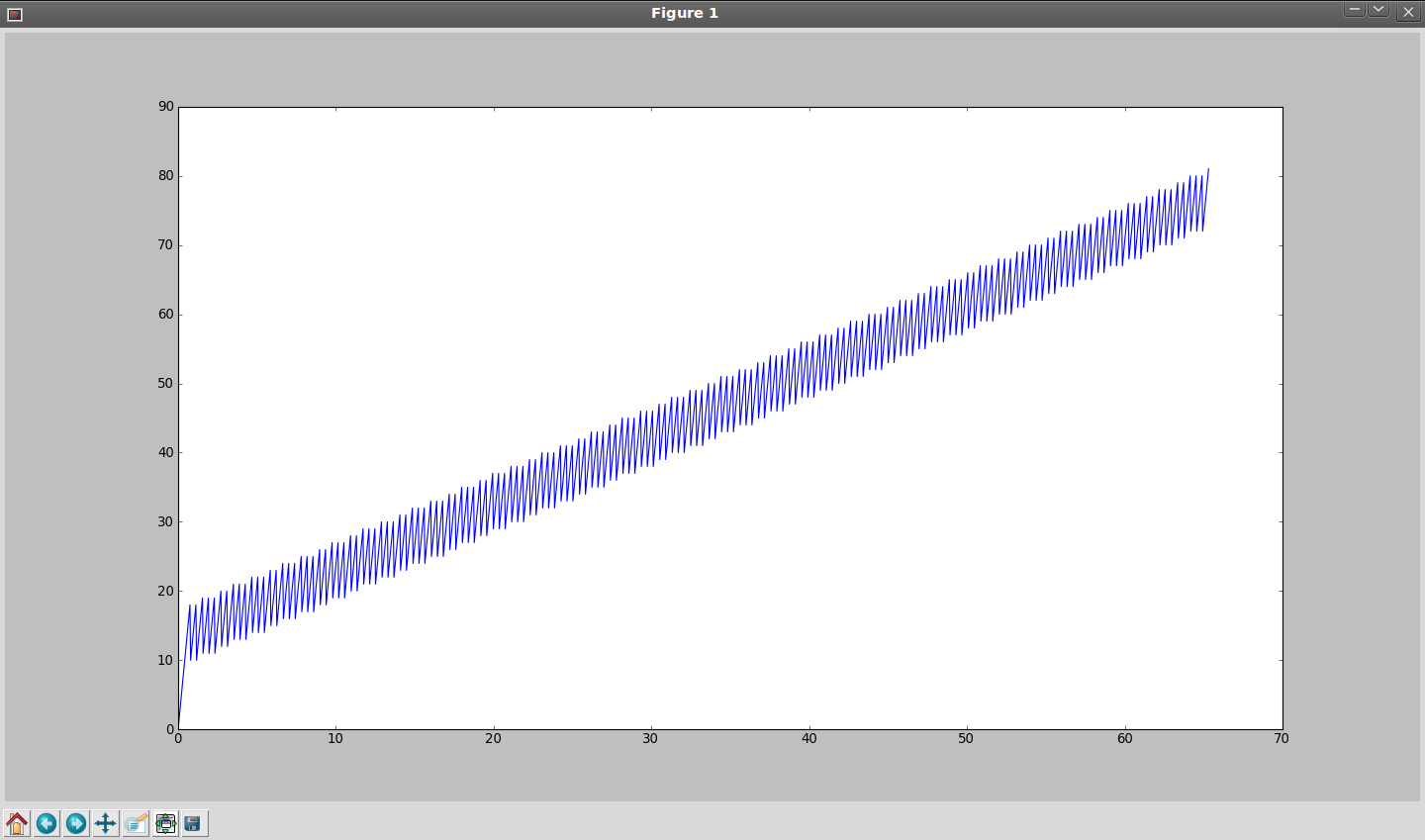
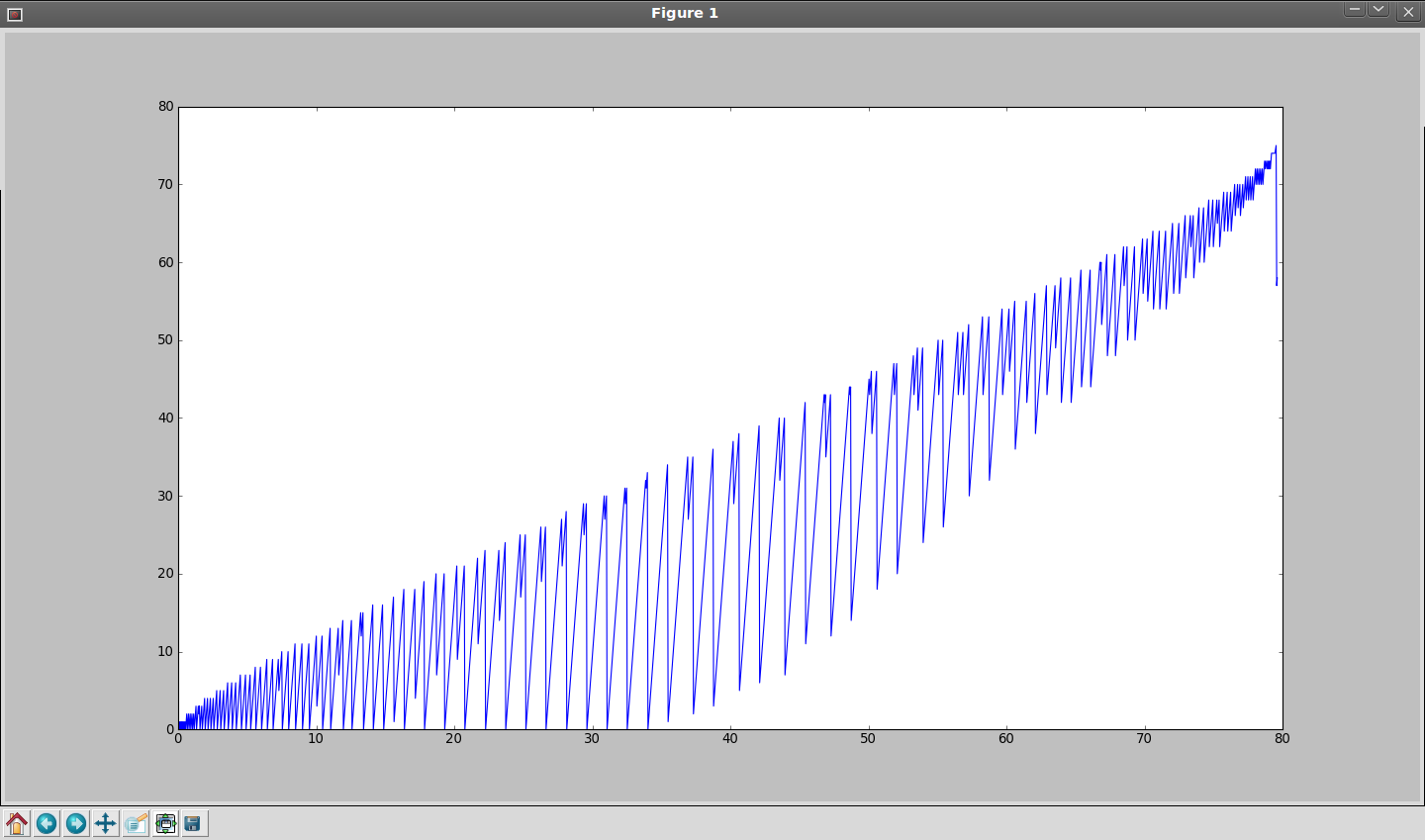
- 8MB + 2x32MB (current method) - 317 frames
- 9x8MB - 1566 frames
- Variable buffering, starting from 8MB + 2x32MB - 1910 frames
[2013-06-20] Ran a few more tests and noticed that it meets or exceeds the performance of the old algorithm with sort/split optimization. There are still some cases where the sort/split method gives 2-3 more frames (no big deal).
Got rid of some spikes, which squeezed a few more frames (1925 or something).
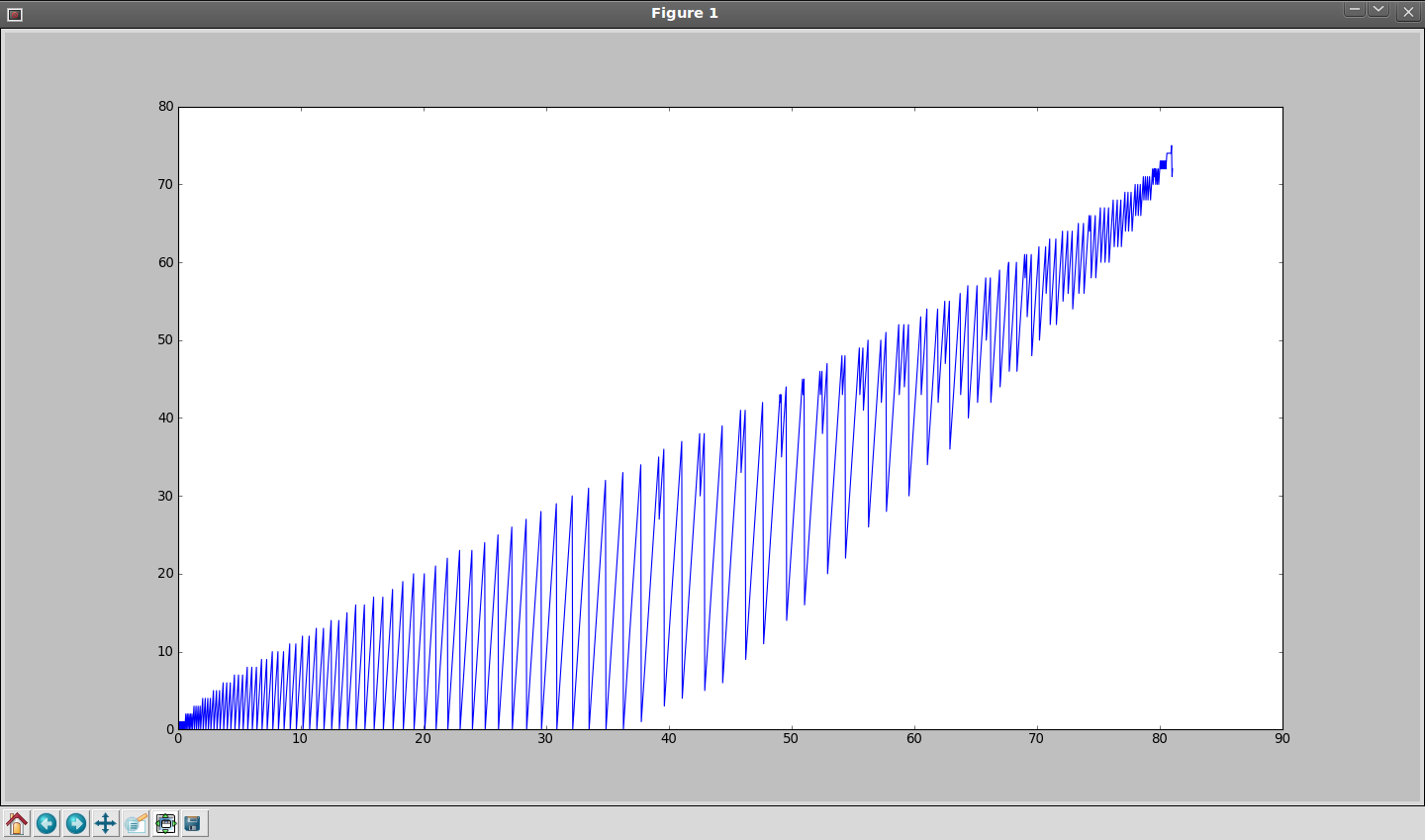
Implemented the algorithm in camera. It's a bit simplified, I didn't include all the optimizations from the simulated version, but at least it sems to work.
Took me two hours just to write this post. Whooo
Enjoy and let me know if the theory actually works!
Fixed broken link - Audionut
During the last few days I took a closer look at the buffering strategy. While it was near-optimal for continuous recording (large contiguous chunks = faster write speed), there was (and still is) room for improvement for those cases when you want to push the recording past the sustained write speed, and squeeze as many frames as possible.
So, I've designed a new buffering strategy (I'll call it variable buffering), with the following ideas in mind:
* Write speed varies with buffer size, like this (thanks to testers who ran the benchmarks for hours on their cameras)
* Noticing the speed drop is small, it's almost always better to start writing as soon as we have one frame captured. Therefore, the new strategy aims for 100% duty cycle of the card writing task.
* Because large buffers are faster than small ones, these are preferred. If the card is fast enough, only the largest buffers will be touched, and therefore the method is still optimal for continuous recording. Even better - adding a bunch of small buffers will not slow it down at all.
* This algorithm will use every single memory buffer that can contain at least one frame (because small buffers are no longer slowing it down).
* Another cause of stopping: when the buffer is about to overflow, it's usually because the camera is trying to save a huge buffer (say a 32MB one), which will take a long time (say 1.5 seconds on slow SD cameras, 21MB/s). So, I've added a heuristic that limits buffer size - so, in this case, if we predict the buffer will overflow after only 1 second, we'll save only 20MB out of 32, which will finish at 0.95 seconds. At that moment, the capturing task will have a 20MB free chunk that can be used for capturing more frames.
* Buffering is now done at frame level, not at chunk level. This finer granularity allows me to split buffers on the fly, in whatever configuration I believe it's best for the situation.
* The algorithm is designed to adjust itself on the fly; for this, it does some predictions, such as when the buffer is likely to overflow. If it predicts well, it will squeeze a few more frames. If not... not
* More juicy details in the comments.
This is experimental. I've ran a few tests, played back a few videos on the camera, but that was all. I didn't even check whether the frames are saved in the correct order.
Build notes
- This breaks bolt_rec. Buffering is now done at frame level, not at chunk level, so bolt_rec has to be adjusted.
- The current source code has debug mode enabled - it prints funky graphs. You'll find them on the card.
- The debug code will slow down the write speed.
- I'd like you to run some test recordings and paste the graphs - this will allow me to check if there's any difference between theory and practice (you know, in theory there isn't any).
- I did not run any comparison with the older method on the camera (I did only in simulation). Would be very nice if you can do this.
- It may achieve lower write speeds. This is normal, because it also uses smaller buffers. If you also consider the idle time, it should be better overall.
- For normal usage, disable the debug code (look at the top of raw_rec.c).
History
[2013-05-17] Experiment about checking the optimal buffer sizes. People ran the benchmarks for hours on their cameras and posted a bunch of logs. They pretty much confirmed my previous theory, that any buffer size between 16MB and 32MB should result in highest speeds.
[2013-05-30] Noticed that file writes aligned at 512 bytes are a little faster (credits: CHDK). Rounded image size to multiples of 64x32 or 128x16 to ensure 512-byte rounding.
[2013-08-06] Figured out that I could just add some padding to each frame to ensure 512-byte rounding and keep the high write speeds without breaking the converters too hard. Also aligned everything at 4096 bytes, which solved some mysterious lockups from EDMAC and brought back the highest speed in benchmarks (over 700MB/s).
[2013-05-30] speedsim.py - First attempt to get a mathematical model of the recording process. Input: resolution, fps and available buffers. Output: how many frames you will get, with detailed graphs. Also in-camera estimation of how many frames you will get with current settings.
[2013-06-18] Took a closer look at these logs and fitted a mathematical model for the speed drop at small buffer sizes.
[2013-06-18] Does buffer ordering/splitting matter? 1% experimented with it before, but there was no clear conclusion.
* is it better to take the highest one first or the smallest one first? there's no clear answer, each one is best for some cases and suboptimal for others.
* since some cameras had very few memory chunks (e.g. 550D: 32+32+8 MB), what if each of the 32MB buffer is divided in 2x16 or 4x8 MB? This brought a significant improvement for resolutions just above the continuous recording threshold, but lowered performance for continuous recording.
* optimization: updated speedsim.py so it finds the best memory configuration for one particular situation. Xaint confirmed the optimization results on 550D.
* problem: there was no one-size-fits-all solution.
[2013-06-19] Simulation now matches perfectly the real-world results. So, the mathematical model is accurate!
[2013-06-19] Started to sketch the variable buffering algorithm and already got some simulation results. There was a clear improvement for borderline cases (settings that require just a little more write speed that your camera+card can deliver).
Example: 550D, 1280x426, 23.976fps, 21.16MB/s, simulation:
- 8MB + 2x32MB (current method) - 317 frames
- 9x8MB - 1566 frames
- Variable buffering, starting from 8MB + 2x32MB - 1910 frames
[2013-06-20] Ran a few more tests and noticed that it meets or exceeds the performance of the old algorithm with sort/split optimization. There are still some cases where the sort/split method gives 2-3 more frames (no big deal).
Got rid of some spikes, which squeezed a few more frames (1925 or something).
Implemented the algorithm in camera. It's a bit simplified, I didn't include all the optimizations from the simulated version, but at least it sems to work.
Took me two hours just to write this post. Whooo
Enjoy and let me know if the theory actually works!
Fixed broken link - Audionut
#8498
Feature Requests / Re: [IMPOSSIBLE] Flash while taking a silent picture
June 20, 2013, 02:53:09 PM
If you know how, be my guest and implement it.
(I don't)
Then try to sync it with the rolling shutter.
(I don't)
Then try to sync it with the rolling shutter.
#8499
Camera-specific Development / Re: Canon 1100D / T3
June 20, 2013, 12:52:19 PM
You can enable a dummy shooting mode (snap simulation) and just let the camera blink and beep. It should be enough to reproduce the bug - of course, if it's not caused by some memory overflow when taking a picture.
There were some changes to timing backend, so it might be related. If the problem happens after exactly X hours/minutes/whatever after powering on the camera, I know where to look.
There were some changes to timing backend, so it might be related. If the problem happens after exactly X hours/minutes/whatever after powering on the camera, I know where to look.